In today’s world, data is ubiquitous, flowing from a multitude of sources such as LinkedIn, Medium, GitHub,
and Substack. To construct a robust Digital Twin, it’s essential to manage not just any data, but data that
is well-organized, clean, and normalized. This article emphasizes the pivotal role of data pipelines in the
current generative AI environment, explaining how they facilitate the effective handling of data from
diverse platforms.
Why Data Pipelines Matter?
Why Data Pipelines Matter
In the era of generative AI, data pipelines are indispensable for several reasons:
Data Aggregation: Generative AI models rely on extensive datasets drawn from various
sources. Data pipelines aggregate information from multiple platforms, ensuring that the data is
comprehensive and well-integrated.
Data Processing: Raw data often needs to be processed before it can be used effectively.
Data pipelines manage tasks such as cleaning, normalization, and transformation, making sure that the data
is in a suitable format for AI models.
Scalability: With the growing volume of data, it’s crucial for data pipelines to be
scalable. They ensure that as data sources increase, the pipeline can handle the load without compromising
performance.
Real-Time Processing: For many AI applications, especially those involving real-time
data, pipelines are designed to process and deliver data swiftly, ensuring that models have access to
up-to-date information.
Consistency and Reliability: Data pipelines provide a structured approach to data
handling, which helps maintain consistency and reliability across different data sources and processing
stages.
Architectural Considerations
Designing an effective data pipeline involves several key architectural decisions:
Source Integration: Identifying and integrating various data sources.
Data Transformation: Implementing processes for cleaning and normalizing data.
Storage Solutions: Deciding on appropriate storage mechanisms for raw and processed data.
Scalability and Performance: Ensuring that the pipeline can scale and perform efficiently
as data volumes grow.
Understanding Data Pipelines: The Key Component of AI Projects
Data is essential for the success of any AI project, and an efficiently designed data pipeline is crucial
for leveraging its full potential. This automated system serves as the core engine, facilitating the
movement of data through various stages and transforming it from raw input into actionable insights.
But what exactly is a data pipeline, and why is it so vital? A data pipeline consists of a sequence of
automated steps that manage data with a specific purpose. It begins with data collection, which aggregates
information from diverse sources like LinkedIn, Medium, Substack, GitHub, and others.
The pipeline then processes the raw data, performing necessary cleaning and transformation. This stage
addresses inconsistencies and removes irrelevant information, converting the data into a format suitable
for analysis and machine learning models.
Why Data Pipelines Are Essential for AI Projects
Data pipelines play a critical role in AI projects for several reasons:
Efficiency and Automation: Manual handling of data is slow and error-prone. Data
pipelines automate this process, ensuring faster and more accurate results, especially when managing large
volumes of data.
Scalability: AI projects often expand in size and complexity. A well-structured pipeline
can scale effectively, accommodating growth without sacrificing performance.
Quality and Consistency: Pipelines standardize data processing, providing consistent and
high-quality data throughout the project lifecycle, which leads to more reliable AI models.
Flexibility and Adaptability: As the AI landscape evolves, a robust data pipeline can
adjust to new requirements without requiring a complete overhaul, ensuring sustained value.
In summary, data is the driving force behind machine learning models. Neglecting its importance can lead
to unpredictable and unreliable model outputs.
The initial step in building a robust database of relevant data involves selecting the appropriate data
sources. In this guide, we will focus on four key sources:
LinkedIn, Medium, GitHub, and Substack.
Why choose these four sources? To build a powerful LLM (Large Language Model) twin, we need a diverse and
complex dataset. We will be creating three main collections of data:
Articles, Social Media Posts, and Code.
Data Crawling Libraries
For the data crawling module, we will use two primary libraries:
BeautifulSoup: This Python library is designed for parsing HTML and XML documents. It helps
create parse trees to efficiently extract data, but it requires page fetching, typically handled by
libraries such as requests or Selenium.
Selenium: This tool automates web browsers, allowing us to interact programmatically with
web pages (e.g., logging into LinkedIn or navigating through profiles). Although Selenium supports various
browsers, this guide focuses on configuring it for Chrome. We have developed a base crawler class to follow
best practices in software engineering.
Raw Data vs. Features: Transforming Data for Your LLM Twin
Understanding the importance of data pipelines in handling raw data is crucial. Now, let’s delve into how
we can convert this data into a format that's ready for our LLM (Large Language Model) twin. This is where
the concept of features becomes essential.
Features are the processed elements that refine and enhance your LLM twin. Think of it like teaching
someone your writing style. Rather than giving them all your social media posts, you’d highlight specific
keywords you frequently use, the types of topics you cover, and the overall sentiment of your writing.
Similarly, features in your LLM twin represent these key attributes.
On the other hand, raw data consists of the unprocessed information gathered from various sources. For
example, social media posts might include emojis, irrelevant links, or errors. This raw data needs to be
cleaned and transformed to be useful.
In our data workflow, raw data is initially collected and stored in MongoDB, remaining in its unprocessed
form. We then process this data to extract features, which are stored in Qdrant. This approach preserves
the original raw data for future use, while Qdrant holds the refined features that are optimized for
machine learning applications.
Cloud Infrastructure: Updating Your Database with Recent Data
In this section, we'll explore how to ensure our database remains current by continuously updating it with
the latest data from our three primary sources.
Before we delve into constructing the infrastructure for our data pipeline, it’s crucial to outline the
entire process conceptually. This step will help you visualize the components and understand their
interactions before diving into specific AWS details.
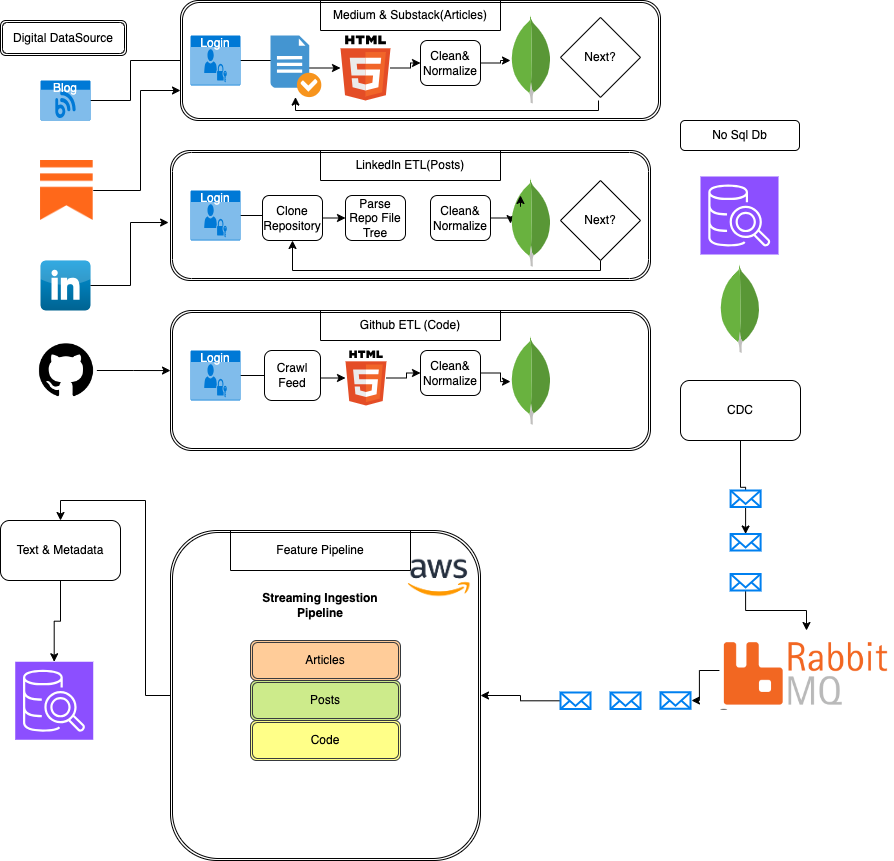
The initial step in building infrastructure is to create a high-level overview of the system components.
For our data pipeline, the key components include:
- LinkedIn Crawler
- Medium Crawler
- GitHub Crawler
- Substack Crawler
- MongoDB (Data Collector)
Wrap-Up: Running Everything
Cloud Deployment with GitHub Actions and AWS
In this concluding phase, we’ve implemented a streamlined deployment process using GitHub Actions. This
setup automates the build and deployment of our entire system to AWS, ensuring a hands-off and efficient
approach. Every push to the .github folder triggers the necessary actions to maintain your system in the
cloud.
For insights into our infrastructure-as-code (IaC) practices, particularly our use of Pulumi, check the
ops folder within our GitHub repository. This exemplifies modern DevOps practices and offers a glimpse
into industry-standard methods for deploying and managing cloud infrastructure.
Local Testing and Running Options
If you prefer a hands-on approach or wish to avoid cloud costs, we offer an alternative. Our course
materials include a detailed Makefile, allowing you to configure and run the entire data pipeline locally.
This is particularly useful for testing changes in a controlled environment or for beginners exploring
cloud services.
For comprehensive instructions and explanations, refer to the README in our GitHub repository.
Conclusion
This article is the second in the series for the LLM Twin: Building Your Production-Ready AI Replica free
course. In this lesson, we covered the following key aspects of building a data pipeline and its
significance in machine learning projects:
- Data collection process using Medium, GitHub, Substack,
and LinkedIn crawlers.
- ETL pipelines for cleaning and normalizing data.
- ODM (Object Document Mapping) for mapping between
application objects and document databases.
- NoSQL Database (MongoDB) and CDC (Change Data Capture)
pattern for tracking data changes and real-time updates.
- Feature Pipeline including streaming ingestion for
Articles, Posts, and Code, with tools like Bytewax and Superlinked used for data processing and
transformation.
This processed data is then managed via RabbitMQ, facilitating asynchronous processing and communication
between services. We explored building data crawlers for various data types, including user articles,
GitHub repositories, and social media posts. Finally, we discussed preparing and deploying code on AWS
Lambda functions.